前言:
java与C++最大的不同点:内存管理java交由虚拟机管理,无需开发用户自己分配与管理,而C++需要自己分配并释放内存。而java内存的回收是由垃圾收集器完成,接下来我们讨论垃圾回收的几个问题:
- 回收那些内存?
- 何时回收?
- 怎么回收?
垃圾回收目标
jvm内存分区及管理请移步java内存管理。在各个类型的内存分区中,栈以及本地方法栈中的内存随着线程或者方法的结束而释放,不需要进行额外的管理。而堆内存里面的实例对象、数组对象都是在编译期不可知的,只有在运行阶段才知道要创建哪些对象,这些内存的分配和回收是动态的,故需要垃圾回收器对这些对象进行操作。
根据一个堆内的对象是否已死决定是否需要回收这个对象,那么如何判定对象已死(没有其他地方引用)呢?目前有两种方法:
- 引用计数法
- 可达性分析法
引用计数法
通过在对象中添加一个引用计数器来记录对象的引用数量,引用这个对象时,数量加1,失效时减1 。这个方法是简单,但是无法解决循环引用的问题。A引用B,B引用A,此时因为相互引用,AB两个对象永远无法回收。
可达性分析法
通过GC Roots对象作为起始点,沿着引用链可以达到的对象不可回收,GC Roots对象的任何引用链都达不到的对象,可以回收。
GC Roots对象:
- 虚拟机栈中引用的对象
- 方法区中静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI引用的对象
引用类型
无论哪种方法判断对象是否存活都引用有关,那么引用除是否有引用外还包括哪些类型呢?
- 强引用:只要强引用存在,垃圾回收器就不会回收
- 软引用:如果内存足够,不回收,若内存不够则第二次垃圾回收时回收
- 弱引用:无论内存是否足够,垃圾回收时都会回收
- 虚引用:不影响生存时间,只是做个标记,回收虚引用对象时收到相应通知
垃圾回收算法
常用的垃圾回收算法有四种:标记清除算法、标记复制算法、标记整理算法、分代收集。
标记清除
标记清除,顾名思义先标记再清除。第一阶段,标记出所有的待回收的对象,第二阶段将标记的对象统一清除并回收内存。
缺点:标记、清除效率低下;产生大量空间碎片。
标记复制
适用于新生代,大多对象朝生夕死适用于标记复制算法。一般按照Eden:Survivor:Survivor为8:1:1进行分配,如图1所示:

新生代的对象存活率不超过10%,例如第一次将Eden+S1分配给新生代使用,Minor GC时,存活的对象不超过10%,此时将所有存活对象复制到S2中,然后清理Eden、S1的内存。之后将Eden+S2分配给新生代使用,当再次进行Minor GC 时,将Eden + S2中存活的对象复制到S1中,并清空Eden、S2的内存。以此反复使用,保证只有一块Survivor的空间是空闲的,利用率可达90%。
标记整理
堆内存中老年代对象的存活率比较高,可能出现垃圾回收时大部分对象都还存活的情况,故此时标记复制算法已经不能满足需求。根据此场景,有一种新的垃圾回收算法可以解决此问题:标记整理算法。
标记整理第一步与之前相同,都是先标记,不过第二步是整理,将存活的对象向一端进行移动,并清理边界以外的内存。如下图2所示,黑色为可回收内存,黄色为存活对象,白色为未使用对象。
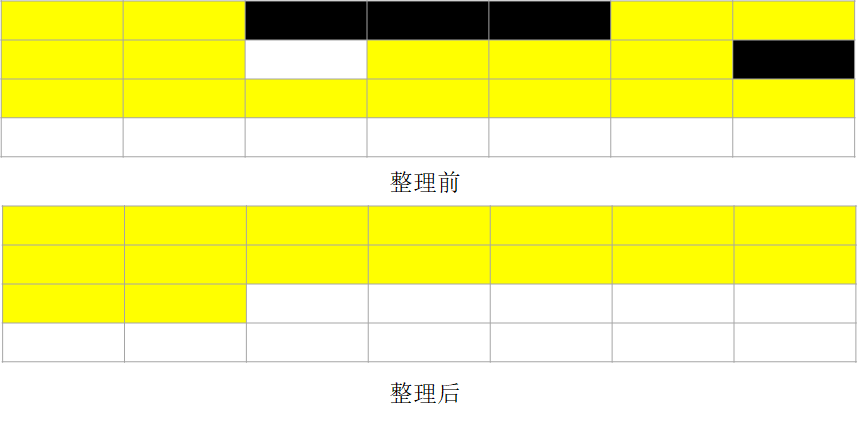
分代收集
将存活对象分为老年代和新生代,不同年代对象采用不同的垃圾回收算法。新生代每次垃圾回收时,大量对象死去,采用标记复制算法;老年代对象的存活率很高,采用标记清除或者标记整理算法。
垃圾回收器
新生代Serial、ParNew、Parallel Scavenge,老年代Serial Old、CMS、Parallel Old,即可应用与老年代也可应用与新生代的垃圾回收器G1 。各个垃圾回收器之间的关系如图3所示:
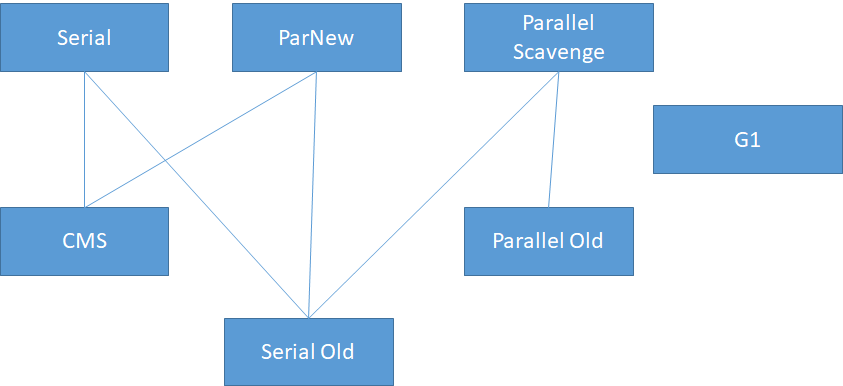
Serial收集器
单线程串行收集器,采用标记复制算法。垃圾回收时需要STW,暂停所有用户进程。Serial收集器的优点是简单高效、没有线程交互的开销,当回收的内存比较小时,停顿时间较少可以接受,故在某些Client模式下的虚拟机比较适合。缺点也很明显,垃圾回收时需要暂停用户线程,体验不好。
ParNew收集器
新生代收集器,采用多线程和标记复制算法。ParNew收集器是Serial收集器的多线程版本,在对新生代垃圾回收时也需要STW,暂停所有用户线程,然后多线程并行的进行垃圾回收,其他环节与Serial类似。当只有一个CPU时,需要线程切换的开销,性能反而不如Serial收集器,当存在多个CPU时,该收集器性能要优于Serial收集器。
Parallel Scavenge收集器
新生代收集器,采用多线程和标记复制算法。特点:吞吐量可控制。吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾回收时间),通过-XX:GCTimeRatio参数控制吞吐量,当参数为19时,用户程序时间/垃圾回收时间 = 19,则吞吐量为19/20 = 95% 。
Serial Old收集器
老年代收集器,采用单线程和标记整理算法。垃圾回收时STW,暂停所有用户线程,然后回收内存。
Parallel Old收集器
老年代收集器,采用多线程和标记整理算法,与Parallel Scavenge一起达到控制吞吐量的效果。在注重吞吐量以及CPU资源的场景可以采用Parallel Scavenge和Parallel Old一起进行垃圾回收。
CMS收集器
多线程并发标记清除收集器,特点是最短回收停顿时间可控。总共分四个阶段:
- 初始标记: STW 多线程执行
- 并发标记:与用户程序并发执行
- 重新标记: STW 多线程执行
- 并发清除:与用户程序并发执行
CMS收集器优点是并发低停顿,缺点也很突出。由于是并发收集故对CPU资源比较敏感;并且无法回收并发清理时用户程序产生的浮动垃圾;标记清楚算法会产生大量的内存碎片,需要定期整理。
G1收集器
G1收集器与其他收集器不同,虽然也强调并发、并行的进行垃圾回收以及采用分代收集的策略,但是在G1不需要与其他垃圾回收器进行搭配使用,可以独立的管理包含新生代、老年代的堆内存。
在G1收集器中,将Java堆划分成多个大小相等的独立区域(Region),新生代与老年代不再是物理隔离,而是同在一个Region中,都是Region的一部分。G1垃圾回收时,整体上看是标记整理算法,局部看两个Region是标记复制算法(两个Region做复制?不太懂)。
其他收集器是将整个Java堆划分老年代、新生代区域,而G1将堆化整为零的分为各个Region,每次回收时,评估Region的回收价值,即花最少的时间回收最多的内存。G1收集器优先回收价值最大的Region区域。垃圾回收时,虽然Region区域是物理上各自独立的,但实际上每个Region中可能的对象可能引用或者被其他Region上的对象所引用。故逻辑上各个Region又是有关系的,那么如何判定对象是否存活?难道要扫描全堆的Region?
针对这种情况,虚拟机采用Remember Set来避免全堆扫描。Remember Set维护了不同Region对象之间的引用关系。若Region A中的对象引用了Region B中的对象,那么Region B中的Remember Set就要记录相关的引用信息。
G1垃圾回收步骤:
- 初始标记: 找出GC Roots对象,STW时间短
- 并发标记:不需停顿用户线程,根据可达性分析法找到存活对象
- 最终标记:修正并发标记期间用户线程导致的变动 STW时间段
- 筛选回收:针对Region回收,其他Region正常使用
性能指标监控
jps 查看虚拟机进程状况
-q 只输出LVMID
-l 带主类全名或者jar包全路径
-v 带JVM启动参数
-m 进程启动时主类main()函数的参数
jstat 虚拟机统计信息工具
-gc/-gcutil/-gccause/-gcnew/-gcnewcapacity/-gcold
1 | $ jstat -gcutil 7488 |
jinfo java配置信息,查看虚拟机各项参数
-flags 查看所有参数
-flag OptionName 查看指定项参数
1 | $ jinfo -flag NewSize 7488 |
jmap java内存映像工具
-dump:[live, ]format=b,file=
1 | $ jmap -dump:format=b,file=idea.bin 7488 |
jhat 虚拟机堆转储快照分析工具
1 | $ jhat idea.bin |
打开localhost:7000,查看分析结果,如下图所示
jstack java栈跟踪工具
1 | $ jstack -l 7488 |

